白皮书

摘要
智能合约是一种新的软件形式,它将彻底改变软件的编写方式、IT 系统的维护方式,以及应用程序及整体业务的构建方式。智能合约是在去中心化区块链上运行的可组合且自治的软件部件,这使得它们无法被篡改和停止。在本文中,我们将介绍互联网计算机(以下简称IC),作为一种全新的区块链设计,IC摆脱了智能合约在传统区块链上的速度、存储成本和计算能力方面的限制,使智能合约的全部潜力得以释放。IC允许智能合约第一次实现完全的去中心化,使得前端到后端都能被托管在区块链上。 IC 由一组加密协议组成,这些协议将独立运行的节点相互连接以组成一个区块链的集合。这些区块链托管并执行"容器(Canister)",即 IC上的智能合约。容器可以存储数据,对数据进行通用计算,并提供完整的技术栈,从而直接为终端用户提供网络服务。计算和存储开销采用“反向GAS模型”,这里需要容器开发人员将IC 的原生代币ICP兑换成cycles进行预付。ICP代币同时也用于治理:IC由去中心化自治组织(以下简称DAO)进行管理,DAO决定变更IC的网络拓扑结构和升级IC协议。
1 引言
1.1 释放智能合约
因其独具的特性,智能合约是 Web3 的关键推动技术,Web3是一种新的获取网络服务的途径,其应用程序完全由用户控制并在去中心化的区块链之上运行。这种去中心化应用程序(以下简称dapps/dapp)通常是代币化的,这意味着项目方本身的代币被分发给用户作为参与dapps的奖励。参与dapps的方式有很多种,包括审核和提供内容来治理dapp,以及创建和维护dapp。通常来说,代币也可以在交易所进行购买;事实上,通常出售代币来为dapp 开发进行融资。最后代币还可以被用于支付dapp提供的服务或内容。运行在目前的区块链平台上的智能合约,包括最主流的这些(诸如以太坊),都会遇到诸多限制,例如较高的交易手续费和存储成本、较慢的运算速度和无法向用户提供前端服务。因此,很多受欢迎的区块链应用并不是完全去中心化的,而是中心化和去中心化混合的状态,程序的大部分托管在传统的云平台中,对链上的智能合约的调用仅为其功能中极小的一部分。不幸的是,这使得这些应用变得不再去中心化,令它们暴露在许多传统云平台托管的程序的缺点之中,例如受制于云平台的服务商和容易发生单点故障。
IC是一个新的运行智能合约的平台。在这里,我们使用术语“智能合约”广义上的定义:一种通用的,防篡改的计算机程序,其在分布式公共网络中自治地执行。
- 通用的,是指智能合约这类程序是图灵完备的(即任何可计算的运算都可以用智能合约完成)。
- 防篡改的,是指程序的指令被可信地执行,并且计算的中间结果和最终结果被准确地存储和/或传输。
- 自治地,是指智能合约被网络自动执行,不需要任何人采取任何行动。
- 分布式公共网络,是指计算机网络可被公开地访问的、地理上分布式的,并且不受少数人或组织控制。
此外,智能合约
- 是可组合的,意味着他们可以彼此交互。
- 支持代币化,意味着他们可以使用和交易代币。
对比现有的智能合约平台,IC在设计上:
- 更具成本优势,特别是允许应用程序以先前平台的一小部分成本,来计算和存储数据;
- 为智能合约的交易处理提供更高的吞吐量和更低的延迟;
- 更具扩展性,特别是IC可以原生地处理无限量的智能合约数据和计算,因为它可以通过向网络中添加节点来提升容量。
智能合约可能具备的另一个特性是不可变性,意味着其一旦部署,智能合约的代码就不能由单方面更改。虽然此特性是某些应用程序所必要的,但是并不是所有的应用程序都需要具备该特性,在智能合约有漏洞需要修复时,不可变性也是一个问题。IC允许智能合约有一系列的可变性策略,从完全不可变到单方面可升级,以及介于两者之间的其他选项。
除了提供智能合约平台之外,IC设计上是一个完整的技术栈,可以构建完全在IC上运行的系统和服务。特别的是,IC上的智能合约可以处理终端用户的HTTP请求,因此智能合约可以直接提供交互式的网络体验。这意味着,构建系统和服务不需要依赖于公司的云托管服务或者私人服务器,从而以一种真正的端到端的方式提供智能合约的所有优势。
实现Web3的愿景。对于终端用户而言,访问基于IC的服务在很大程度上是透明的。他们的个人数据比在访问公有云或私有云的应用时更安全,但是与应用程序的交互体验是一样的。
然而,对于创建和管理基于IC的服务的人来说,IC消除了许多在开发和部署当前的应用程序和微服务时的成本、风险和复杂性。例如,在当前垄断互联网的科技巨头们所推动的整合下,IC平台提供了另一种选择。此外,IC安全的协议可以确保消息的可靠传递、透明可追溯,以及不需要依赖于防火墙、备份设施、负载均衡服务器和故障编排就可以实现的网络弹性。
构建IC就是要互联网回归其开放,创新和创造性的本源——换言之,实现Web3的愿景。针对一些特别的示例,IC做了下述的事:
- 提供互操作性,共享函数,持久化APIs和无主应用程序,上述的所有特点减少了平台的风险,并鼓励创新和协作。
- 自动持久化数据于内存中,无需数据库服务器和存储管理,提升了计算效率并简化了软件开发。
- 简化了IT组织需要集成和管理的技术栈,提升了运营效率。
1.2 高阶视角下的IC
大致上,IC是一个与复制状态机(replicated state machines)交互的网络。复制状态机在分布式系统[Sch90]中是一个相当标准的概念,但是我们在这里仍然简单介绍下,从状态机的概念开始。
状态机是一种特定的计算模型。此类机器维护着一个状态,即对应普通计算机中的主内存或是其他形式的数据存储。此类机器按离散的轮次进行执行:每一轮中,它接受一个输入,对输入和当前状态应用一个状态转换函数,获得一个输出和一个新的状态。这一新状态将变成下一轮次的当前状态。
IC中的状态转换函数是一个通用函数,意味着一些存储在状态中的输入和数据可能是任意的程序,这些程序会作用于其他的输入和数据。因此,这样的一个状态机代表了一个通用(即图灵完备)的计算模型。
为了实现容错性,状态机可以被复制。复制状态机包含由节点副本(replicas)组成的子网,其中每一个节点副本运行相同状态机的副本。即使某些节点副本发生故障,子网也应当继续—并且正常运转。
子网中的每个节点副本都必须按照相同的顺序处理相同的输入。为此,子网中的节点副本必须运行共识协议[Fis83],来确保子网中的所有节点副本按照相同的顺序处理输入。因此,每一个节点副本的内部状态将按照相同的方式随时间演变,并且每个节点副本会生成完全相同序列的输出。需要注意的是,IC上复制状态机的输入可以是由外部用户生成的输入,也可以是另一台复制状态机生成的输出。类似地,复制状态机的输出可以作为输出导向外部用户,也可以作为输入导向另一台复制状态机。
1.3 故障模型
在计算机科学的分布式系统领域中,通常会考虑两种类型的节点副本故障:宕机故障和拜占庭故障。宕机故障发生在节点副本突然停机并且无法恢复时。拜占庭故障是节点副本可能用任何方式偏离规定的协议。而且,在拜占庭故障下,一个或多个节点副本可能直接处于恶意对手方的操控之中,其可以操纵这些节点副本的行为。在这两种故障类型中,拜占庭故障具有更大的潜在破坏性。
共识协议和实现复制状态机的协议通常会假设多少节点副本可能发生故障以及发生何种程度的故障(宕机或拜占庭)。IC中假设一个给定的子网若有个节点副本,那么发生故障的节点副本少于,并且这些故障可能是拜占庭式。(需要注意的是,IC中的不同子网规模不同。)
1.4 通信模型
共识协议和执行复制状态机通常也会对通信模型作出假设,描述了对手方延迟节点副本间消息传递的能力。在两个对立端下,我们有如下的模型:
- 在同步模型中,存在已知的有限时间限制 ,因此对于发送的任意消息,它会在小于的时间内递达。
- 在异步模型中,对于发送的任意消息,对手方可以延迟其传递任意有限时间,因此对于传递消息没有时间限制。
由于IC子网中的节点副本通常分布在全球,同步通信模型非常不切实际。事实上,攻击者可以延迟诚实节点副本或是延迟诚实节点副本间的通信,来破坏协议的正确行为。这种攻击通常比控制和破坏诚实节点副本更容易实施。
在全球分布的子网的设定下,最可行和健壮的模型是异步模型。不幸的是,目前没有已知的共识模型在异步模型下是真正可行的(最近的异步共识协议,如[MXC^+^16],可以达到可观的吞吐量,但是延迟不太好)。所以同其他大多数不依赖于同步通信的实用拜占庭容错系统(例如[CL99], [BKM18], [YMR^+^18])一样,IC选择了一种折衷的方案:部分同步通信模型[DLS88]。这样的部分同步模型可以有多种构建方式。IC使用的部分同步模型假设,大致上讲,每个子网中节点副本的通信在很短的时间间隔内是周期性同步的;此外,同步时间限制不需要被提前知晓。建立这种部分同步假设仅仅是为了确保共识协议的进行(所谓的活性)。确保共识的正确性(所谓的安全性)并不需要这种部分同步假设,同样在IC协议栈的其他任何地方也不需要。
在部分同步和拜占庭故障的假设下,众所周知的是,我们对于故障节点数量的限制是最优解。
1.5 权限模型
最早的共识协议(例如PBFT[CL99])是有许可的,也就是说构成复制状态机的节点副本是受一个中央组织管理,其决定了哪些实体可以提供节点副本,网络的拓扑结构,并且可能还实现了某种中心化的公钥基础设施。许可共识机制通常效率是最高的,尽管它们避免了单点故障,但是中心化管理对于特定的应用程序是不可取的,并且这违背了蓬勃发展的Web3时代的精神。
最近,我们看到了无许可的的共识协议的兴起,例如Bitcoin[Nak08],Ethereum[But13]和Algorand[GHM^+^17]。这些协议基于区块链,采用工作量证明(以下简称PoW)(例如Bitcoin,Ethereum2.0之前)或是权益证明机制(以下简称PoS)(例如Algorand,Ethereum2.0)。尽管这些协议是完全去中心化的,但是他们比有许可的协议效率更低。我们也需要指出,正如[PSS17]所观察到的,基于PoW机制的共识协议例如Bitcoin,在异步通信网络下并不能保证正确性(即安全性)。
IC的权限模型是一个混合模型,在拥有有许可协议的效率的同时提供去中心化PoS协议的许多好处。这个混合模型叫做DAO控制网络(DAO-controlled network),(大致上讲)按如下机制工作:每个子网运行一个有许可的共识协议,但是由一个DAO决定哪些实体可以提供节点副本,配置网络的拓扑结构,提供公钥基础设施,并且控制节点副本部署的协议版本。IC的DAO被称为网络神经系统(以下简称NNS),基于Pos,因此所有NNS的决策都由社区成员决定,社区成员的投票权由其在NNS中质押的IC原生治理代币(关于该代币的细节详见章节1.8)数量决定。通过这个基于PoS创建的治理系统,可以创建新的子网,可以在现有子网中增加或者移除节点副本,可以部署软件更新并且可以对IC进行其他调整。NNS本身是一个复制状态机,(和其他状态机一样)运行在特定的子网上,其成员资格由同一套基于PoS的治理系统所决定。NNS维护一个称为注册表的数据库,跟踪IC的拓扑结构:哪些节点副本属于哪个子网,节点副本的公钥等等。(关于NNS的更多细节详见章节1.10。)
因此,人们看到IC的DAO控制网络既允许IC获得许可网络的很多实用优势(在更有效的共识方面),也保留了去中心化网络的许多优势(在DAO治理下)。
运行IC协议的节点副本托管在地理上分布式的、独立运行的数据中心之上。这也增强了IC的安全性和去中心化性。
1.6 链钥密码学(Chain-key cryptography)
IC的共识协议确实使用了区块链,但它也采用了公钥加密技术,特别是电子签名:NNS维护的注册表用于将公钥绑定至节点副本及子网形成一个整体。这实现了一个独一无二的强大技术集合,我们称之为链钥密码学,它有几个组成部分。
1.6.1 阈值签名
链钥密码学的第一个组成部分是阈值签名:阈值签名是一个成熟的加密技术,它允许子网拥有一个公共的验证签名密钥,对应的签名私钥分成片段分配给子网中的节点副本,而分配保证作恶节点无法伪造任何签名,而诚实节点拥有的私钥片段可以允许子网生成符合IC原则和协议的签名。
- 这些阈值签名的一个关键应用在于
- 一个子网的单独输出可以由另一个子网或是外部用户进行验证,验证可以简单地利用该子网(第一个子网)的公共验证签名密钥来验证电子签名实现。
需要注意的是,子网的公共验证签名密钥可以从NNS中获取—该公共验证签名密钥在子网的生命周期中保持不变(即使子网的成员在该生命周期中可能发生变化)。这与许多不可扩展的区块链协议形成鲜明的对比,其需要验证整个区块链来验证单个输出。
正如我们所看到的,这些阈值签名在IC中还有许多其他应用。一个应用于让子网中的每个节点副本可以访问无法预测的伪随机数位(衍生于此类阈值签名)。这是共识层使用的随机信标和执行层使用的随机磁带的基础。
为了安全地部署阈值签名,IC采用了创新性的分布式密钥生成(以下简称DKG)协议,来构建公共签名验证密钥,并为每个节点副本提供对应签名私钥的一个片段,用于我们的故障和通信模型。
1.6.2 链演进技术(Chain-evolution technology)
链钥密码学也包括一系列复杂的技术,用于随时间推移健壮和安全地维护基于区块链的复制状态机,合起来我们称之为链演进技术。每个子网在包含多轮(通常大约是几百轮)的时期(Epoch)内运行。利用阈值签名和其他一些技术,链演技术实现了许多按时期定期执行的基本维护工作,:
垃圾回收:在每一时期的末尾,所有已经被处理的输入以及所有排序这些输入所需要的共识层消息,可以安全地从每个节点副本的内存中清除。这对防止对于节点副本的存储需求的无限增长至关重要。这也与许多不可扩展的区块链协议形成对比,它们必须存储从创世区块开始的整个区块链。
快速转发:如果一个子网中的节点副本大幅落后于其同步节点(因为其宕机或是网络断连很长时间),或是一个新的节点副本被添加入子网,他们可以通过快速转发至最新时期的起始点,不需要运行共识协议并处理该点之前的所有输入。这也与许多不可扩展的区块链协议形成对比,它们必须处理从创世区块开始的整个区块链。
子网成员变更:子网的成员(由NNS决定,详见章节1.5)可能会随着时间变化。这仅可能发生在时期的边缘,需要小心操作以确保一致且正确的行为。
主动秘密再共享:我们在上面的章节1.6.1中提到IC是如何使用链钥密码学——具体来说,阈值签名——来进行输出验证。它基于的就是秘密共享,通过将一个秘密(在这里就是签名私钥)拆分成片段分别存储在节点副本中,从而避免了任何单点故障。在每个时期开始时,这些片段都会被主动再共享。这实现了两个目标:
- 当一个子网的成员发生变动时,再共享可以确保任何新成员都有相应的秘密片段,而任何不再是成员的节点副本就不再会拥有秘密片段。
- 如果在任意一个时期,甚至每个时期都有少量的秘密片段被泄露给攻击者,这些片段也不会帮助到攻击者。
协议升级:如果IC协议本身需要升级,修复漏洞或是增加新功能,可以在时期开始时通过特殊协议自动完成。
1.7 执行模型
如前所述,IC的复制状态机可以执行任意的程序。IC中的基本计算单元叫做容器,它和进程的概念大致相同,包含了程序和其状态(随时间变化)。
容器的程序用WebAssembly(以下简称Wasm)进行编码,是一种基于堆栈的虚拟机的二机制指令格式。Wasm是一种开源标准1。尽管它最初设计是为了实现网页端的高性能应用,但它也非常适合用于通用计算。
IC提供了一个运行时环境,用于容器内执行Wasm程序,并(通过消息传递)与其他容器和外部用户通信。虽然原则上可以用任何能编译成Wasm的语言去编写容器程序,但我们设计了一个叫做Motoko的语言,它与IC的操作语义十分一致。Motoko是一种强类型,基于actor2的编程程序,内置支持正交持久性3和异步消息传递。正交持久性意味着容器维护的内存会自动持久化(即不必写入文件)。Motoko具有许多生产力和安全特性,包括自动内存管理,泛型,类型推断,模式匹配,以及任意和固定精度的算术。
除了Motoko之外,IC还提供了一个消息接口定义语言和数据格式称为Candid,用于固定类型、高级语言及跨语言互操作性。这使得任何两个容器,即使是用不同的高级语言编写,也可以轻松地相互通信。
为了提供全面支持任何给定编程语言的容器开发,除了该语言的Wasm编译器外,还必须提供特定的运行时支持。当前除了Motoko之外,IC还全面支持了Rust编程语言的容器开发。
1.8 功能代币
IC使用称为ICP的功能代币。该代币有如下功能:
NNS质押:如章节1.5所述,ICP可以用于在NNS中质押获得投票权,从而参与控制IC网络的DAO。在NNS中质押代币并参与NNS治理的用户还会收到新铸造的ICP代币作为投票奖励。奖励数量由NNS制定和执行的政策所决定。
兑换Cycles:ICP用于支付IC的使用费用。更具体来说,ICP可以兑换成cycles(即销毁),这些cycles可以用于支付创建容器(详见章节1.7)和容器所使用的资源(存储,CPU和带宽)费用。ICP兑换成cycle的比例由NNS决定。
支付节点提供者:ICP用于支付节点提供者—这些实体拥有和运营着计算节点,来托管构成IC的节点副本。NNS定期(当前每月)决定每个节点提供者应收到的新铸造代币并发放至其账户。根据NNS制定和执行的政策,支付代币的前提是节点提供者为IC提供可靠的服务。
1.9 边界节点
边界节点提供IC的网络边缘服务。特别是,他们提供了
- 明确定义的IC入口
- IC的拒绝服务保护
- 从传统客户端(例如网页浏览器)无缝访问IC
为了可以从传统客户端无缝访问IC,边界节点提供了对应的功能,将用户的标准HTTPS请求转换成指向IC容器的输入消息,随后将该输入消息路由至容器所在子网的特定节点副本。而且,边界节点提供了改善用户体验的额外服务:缓存,负载均衡,速率限制以及传统客户端验证来自IC响应的能力。
容器通过ic0.app域名上的URL链接进行标识。初始条件下,传统客户端会寻找URL链接对应的DNS记录,获取边界节点的IP地址,随后发送一个初始的HTTPS请求至该地址。边界节点返回一个基于JavaScript的“服务工作机(service worker)”,以运行于传统客户端。在此之后,传统客户端和边界节点的所有交互都通过这个service worker完成。
Service worker的一项基本任务是利用链钥密码学(详见章节1.6)验证来自IC的响应。为此,NNS公共的验证密钥被硬编码在service worker内。
边界节点本身负责将请求路由至托管特定容器的子网节点副本。边界节点执行路由所需要的信息从NNS中获取。边界节点保管着一个可以及时响应的节点副本列表并从中随机选择一个。
传统客户端与边界节点间,边界节点与节点副本之间的通信安全都由TLS4保证。
除了传统客户端外,还可以使用“IC原生”客户端与边界节点交互,其已经包含了service worker的逻辑,不需要向边界节点取回service worker程序。
和节点副本一样,边界节点的部署和配置由NNS控制。
1.10 NNS的更多细节
如章节1.5所述,网络神经系统(NNS)是一个控制IC的算法治理系统。它通过特殊的系统子网中的一组容器实现。该子网和其他子网类似,但配置有所不同(例如,系统子网中的容器不收取cycles费用)。
其中最重要的一些NNS容器是
- 注册表容器,存储着IC的配置信息,即哪些节点副本属于哪个子网,子网和节点副本的公钥等等。
- 治理容器,管理着IC协议如何演进的决策制定和投票。
- 账本容器,记录用户的ICP代币账户和相互间的交易。
1.10.1 NNS的决策制定
任何人通过在所谓的神经元(neurons)中质押ICP代币参与NNS治理。神经元的持有者可以提议关于IC应该如何变更的提案并投票,例如子网的拓扑结构或者协议该如何变更。神经元的投票权利是基于PoS的。直观地说,质押更多ICP的神经元投票权利更大。但是,投票权也取决于神经元的其他特征,例如愿意质押代币更长时间的神经元持有人,被赋予了更大的投票权。
每一个提案有确定的投票期限。如果投票期结束时,参与投票的简单多数赞成该提案,并且赞成票数超过了给定的总投票权法定人数要求(现在是3%),则该提案被采纳。否则,该提案被否决。除此之外,任何时候只要绝对多数(超过总投票一半)赞成或反对该提案,该提案相应被采纳或否决。
如果提案被采纳,治理容器会自动执行决策。例如,如果一个提案提议改变网络的拓扑结构并且被采纳,治理容器将自动使用新配置来更新注册表容器。
1.11 当前工作
IC的架构仍在不断演进和扩展。以下是一些即将部署的新功能:
DAO控制容器。就像IC的整体配置是由NNS控制一样,任意的容器也可以由其自身的DAO控制,称为服务神经系统(以下简称SNS)。控制容器的DAO可以更新容器逻辑,也可以下达特殊权限命令让容器执行。
ECDSA阈值签名。ECDSA签名[JVM01]被用于加密货币,如Bitcoin和Ethereum,以及许多其他应用程序。虽然阈值签名已经是IC中的重要组成部分,但并不是ECSDA阈值签名。而这项新特性将允许单个容器控制ECDSA签名密钥,这些签名密钥安全地分布在托管该容器子网的节点副本中。
Bitcoin和Ethereum集成。基于新的ECDSA阈值签名,这一特性将允许容器与Bitcoin和Ethereum链交互,包括直接签名链上交易。
HTTP集成。此功能将允许容器读取任意网页(IC外部的)。
2 架构概述
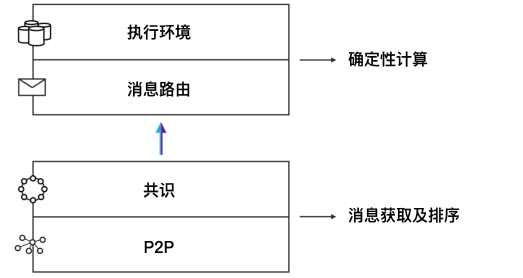
如图1所示,IC协议包括四层:
链钥密码学在多个层中都有应用,将分别在第3章(阈值签名)和第8章中(链演进技术)详细介绍。
2.1 P2P层
P2P层的任务在子网的节点副本中传递协议消息。协议消息包括
- 用于实现共识的消息
- 外部用户发起的输入消息
P2P层基本上提供的是一个“尽力而为(best effort)“的广播通道:
如果一个诚实的节点副本广播了一条消息,那么这条消息最终将会被子网中的所有诚实节点所接收。
P2P层的设计目标如下:
- 有限资源. 所有的算法都在有限的资源(内存,带宽,CPU)下运转。
- 优先级. 根据特定的属性(例如类型,大小和轮次),不同的消息将按照不同的优先级进行排序。并且这些优先级的规则可能会随着时间而改变。
- 高效. 高吞吐量比低延迟更重要。
- 抗DOS/SPAM. 故障节点将不会影响诚实节点副本间的相互通信
2.2 共识层
IC共识层的任务是对输入消息进行排序,以确保所有的节点副本按照相同的顺序处理输入消息。现在已有很多文献中的协议是为了解决这一问题。IC采用了一种全新的共识协议,本文将用概括性的语言对其进行阐述。
任何安全的共识协议都应当确保两个属性,大体上就是:
- 安全性: 所有的节点副本都事实上同意相同的输入顺序,和
- 活性:所有的节点副本都应当逐一更新状态。
IC共识层的设计目标
- 极其简单,和
- 健壮:当存在个别恶意节点时,性能会柔性下降。
如上所述,我们假设作恶节点(即拜占庭容错)。同时,IC在部分同步网络的假设下可以确保协议的活性,而协议的安全性甚至在完全异步的网络下依然可以保证。
像许多的共识协议一样,IC共识协议是基于区块链的。伴随着协议的推进,以创世区块为根节点的区块树将不断生长。每一个非创世区块都包含一个荷载(payload),由一系列输入和父区块的哈希组成。诚实的节点副本对这个区块树有一致的视角:尽管每个节点副本可能对这个区块树有不同的局部视角,但是所有的节点副本看到的都是这一相同的区块树。此外,伴随着协议的推进,区块树中总会有一条最终确认区块的路径。同样地,诚实节点副本对这一路径有一致的视角:尽管每个节点副本可能对这条路径有不同的局部视角,但是所有的节点副本看到的都是这一相同的路径。沿着这条路径的区块的荷载中的输入,是已经排序好的输入并将由IC的执行层进行处理。
IC的共识协议按照轮次进行处理。在轮次中,一个或多个块高的区块被添加到区块树中。也就是说,在轮次添加的区块,距离根节点的距离都是。在每一轮中,将通过伪随机过程给每一个节点副本分配一个唯一的排位,范围是的整数。这一伪随机过程使用了随机信标(Random Beacon,使用了阈值签名技术,在章节1.6.1中已经提及并将在第3章进行详述)来实现。排位最低的节点副本是该轮次的主节点。当主节点是诚实的并且网络同步时,主节点会提议一个新区块,并加入到区块树中;此外,这将会是该轮次唯一添加到区块树中的区块,并延伸最终确认的路径。如果主节点不诚实或者网络不同步状态,其他排位更高的节点副本也可以提议新区块,并将其添加到区块树中。在任何情况下,协议逻辑给予主节点提议的区块最高优先级,并且某些区块会在该轮次被加入到区块树中。即使协议在没有延伸最终确认路径的情形下继续执行,区块树的高度也会在每轮继续增长,这样最终确认路径会在轮次继续延伸,使其长度达到。上述做法下,即使故障节点或不可预测的高网络延迟导致延迟增加,整体协议的吞吐量大体上依旧维持稳定。
共识协议依赖于电子签名在节点副本中去验证消息。为实现这一点,每一个节点副本都与签名协议的一个公共验证密钥相关联。而节点副本和公钥之间的关联性可以从NNS维护的注册表中获取。
2.3 消息路由
如章节1.7中所述,IC中的基本计算单元叫做容器。IC提供了运行环境,使得容器中可以执行程序,并可以(通过消息)与其他容器和外部用户通信。
共识层将输入打包进区块的荷载中,并随着区块被最终确认,相应的荷载会被传递给消息路由层并由执行环境处理。执行层将随之更新复制状态机中相应容器中的状态,并将输出交由消息路由层处理。
有必要区分两种输入类型:
入口消息:来自外部用户的消息
跨子网消息:来自其他子网的容器的消息
我们同样可以区分两种输出类型:
入口消息响应:对于入口消息的响应(可被外部用户取回)
跨子网消息:传输给其他子网容器的消息
当收到来自共识的负载后,这些负载中的输入会被置入不同的输入队列。对于一个子网下的每一个容器 ,都存在多个输入队列:用于发给的的入口消息,用于和通信的每一个别的容器'(如果和不在同一个子网,将会是跨子网消息)。在每一轮中,执行层都会消耗这些队列中的一些输入,更新相应容器中的复制状态,并将输出置于不同的输出队列中。对于一个子网下的每一个容器,都存在多个输出队列:对于每一个与通信的容器,都有其各自的队列(如果和不在同一个子网,将会是跨子网消息)。消息的路由层将取得消息队列中的消息并置入子网间数据流,以被跨子网传输协议处理 ,该协议的工作是将这些消息实际传输到其他子网。
除了这些输出队列外,同时存在一种入口历史的数据结构。一旦一条入口消息已被容器处理,对该条入口消息的响应将被记录在该数据结构中。此刻,提供该条入口消息的外部用户将能够获取相关的响应。(注意入口历史并不保留所有入口消息的完整历史)
需要注意的是,节点副本的状态包括容器的状态以及“系统状态”。“系统状态”包括上述提及的队列,数据流以及入口历史的数据结构。因此,消息路由层和执行层同时参与更新和维护子网的副本状态。此状态应全部在完全确定性的原则下被更新,这样所有的节点都会维护完全相同的状态。
另外需要注意的是,共识层解耦于消息路由层以及执行层,也就是说传入荷载之前,共识区块链中的任何分叉都已经被解决了。事实上,共识层允许提前运行,并不需要和消息路由层保持完全一致的进度。
2.3.1 每轮认证状态(Per-round certified state)
在每一轮中,子网的一部分状态会被验证。每轮认证状态采用链钥密码学进行验证。除了别的之外,给定轮次中的验证状态包括
- 最近添加到子网间数据流中的跨子网消息
- 其他元数据,包括入口历史的数据结构
每轮认证状态利用了阈值签名技术验证(详见章节1.6.1)。在IC中每轮认证状态被用于如下几个方面:
- 输出验证. 跨子网消息和入口消息响应都使用每轮认证状态进行验证。
- 防范和识别非确定性.共识层保证了每个节点副本按相同的顺序处理输入消息。因为每个节点副本确定性得处理消息,应当会得到相同的状态。但是IC额外设计了一层确保健壮性,来防止和识别任何意外的非确定性计算的发生。每轮认证状态是该机制中的一环。
- 与共识层协作. 每轮认证状态还通过两种方式和执行层和共识层进行协作:
- 如果共识层运行快于执行层(进度由上一轮经认证状态决定),共识层会被“降速”。
- 共识层的输入必须经过特定的有效性验证,这些验证取决于所有节点副本已达成共识的验证状态。
2.3.2 查询调用(query calls)和更新调用(update calls)
正如我们之前所述,所有的入口消息必须经过共识,才能被子网的所有节点副本按相同的顺序进行处理。但是,针对那些处理时不会变更状态的入口消息,可以进行一项重要的优化。他们被称为查询调用—而相对的其他入口消息,被称为更新调用。查询调用被允许进行只读或是可能改变容器状态的计算,但是任何对节点副本状态的更新都不会被提交给复制状态。正因如此,查询调用可以被单个节点副本直接处理而不需要经过共识,这极大的降低了从查询调用获得响应的延迟。
一般而言,对查询调用的响应不会记录在入口历史的数据结构中,因此也不可以用之前的每轮认证状态进行验证。然而,IC使容器可以存储数据(在处理更新调用时)在特殊的认证变量中(certified variables),可以利用这一机制验证数据的有效性;这样的话,查询调用可以返回值并存储在经认证变量中,仍然可以被验证。
2.3.3 外部用户验证(External user authentication)
入口消息和跨子网消息的一个主要区别在于用于验证消息的机制。链钥密码学用于验证跨子网消息,另一个不同的机制用于来自外部用户的入口消息。
IC中没有外部用户的中央注册表。相反,外部用户通过一串公钥哈希作为用户标识(又称principal)来向容器来标识自己。用户自己持有对应的签名密钥,用来签署入口消息。签名和公钥会随着入口消息一起发送。IC将自动验证签名并传递用户标识给到对应的容器。随后该容器根据用户标识和入口消息中指定操作的其他参数,批准请求的操作。
新用户在首次与IC交互时会生成一对密钥对并从公钥中衍生出他们的用户标识。老用户根据存储在用户代理中的私钥完成验证。用户还可以用签名委托的方式,将多个密钥对关联到一个用户身份上。该特性非常有用,因为它允许了一个用户在多个设备上通过相同的用户身份证明来访问IC。
2.4 执行层
执行层一次处理一个输入消息。这一输入消息取自输入消息队列,并导向到一个容器。根据此输入消息和该容器的状态,执行层环境将更新容器的状态,另外将消息加入输出队列并更新入口历史(可能包括对更早的入口消息的响应)。
每个子网都可以访问分布式伪随机生成器(PRG)。二进制伪随机数的种子是被称为随机磁带(Random Tape)(参见章节1.6.1,详见[第3章](#3 链钥密码学I:阈值签名))的阈值签名。共识协议的每一轮都会有一个不同的随机磁带。
随机磁带的基本特性有
- 在块高的区块被任意诚实节点副本确认之前,块高的随机磁带是不可预测的。
- 在块高的区块被任意诚实节点副本确认的时间点前,节点副本已经有构建块高的随机磁带的所有片段
例如在轮次时,子网为获得二进制伪随机数,需要从执行层发起“系统调用”。系统随后将响应块高+1的随机磁带。根据上述的特性(1),协议保证在子网发送请求时,请求的二进制伪随机数不可预测。事实上,共识层会将随机磁带和荷载都传递给消息路由层;根据上述的特性(2),一般不会引起任何额外的延迟。
2.5 组合阐述
我们追踪记录一个用户请求在IC上的典型流程。
查询调用
- 用户通过用户端向边界节点(详见章节1.9)发送对于容器的请求消息,边界节点将消息发送给托管着容器的子网节点副本。在收到后,节点副本将计算响应并通过边界节点发回给用户。
更新调用
用户通过用户端向边界节点(详见章节1.9)发送对于容器的请求消息,边界节点将消息发送给托管着容器的子网节点副本。
接收到消息后,该节点副本通过P2P层(详见章节2.1)向子网中的所有节点副本广播消息。
在接收到消息的情况下,共识层下一轮的主节点(详见章节2.2)会将消息和其他输入一同打包进其提议的区块。
一段时间之后,区块被最终确认,其荷载被发送至消息路由层(详见章节2.3)进行处理。需要注意的是,P2P层同样用于共识层去确认区块。
消息路由层会将消息放置在容器的输入消息队列中。
一段时间之后,执行层(详见章节2.4)会处理消息,并更新容器的内部状态。
在一些情况下,容器立即能够计算对于请求消息的响应。在这种情况下,响应会被记录在入口历史的数据结构中。
在其它情况下,处理请求消息需要向别的容器发起请求。在这个例子中,我们假设为处理请求消息,容器需要向另一个子网的另一个容器发起请求。这第二个请求会被放置在容器的输出队列中,然后接下去的几步将被执行。
一段时间之后,消息路由层会将调用请求移动到合适的跨子网数据流中,最终将会被传输到托管容器的子网。
在第二个子网中,获取来自第一个子网的请求后,其会通过共识层和消息路由,最终由执行层进行处理。第二个子网的执行层会更新容器的内部状态,然后生成对于请求的响应。响应会进入容器的输出队列,最终放置在跨子网数据流中被传输回第一个子网。
回到第一个子网,当其获取来自第二个子网的响应后,响应经由共识层和消息路由层,并最终由执行层进行处理。第一个子网的执行层会更新容器的内部状态,然后生成对于原始请求的响应。这一响应会被记录在入口历史的数据结构中。
无论是哪条执行路径,对于请求消息的响应,最终会被记录在托管容器的子网的入口历史数据结构中。为了获取这一响应结构,用户端必须执行“查询调用”(详见章节2.3.2和更新调用(update calls))。就像在章节2.3.1中所阐述的,这一响应可以被链钥密码学(具体来说,使用的是阈值签名技术)进行验证。这一验证逻辑本身(即阈值签名认证)可以被用户端执行,其使用了最初从边界节点获取的service worker。
3 链钥密码学I:阈值签名
IC的链钥密码学的一个关键组成部分是阈值签名方案[Des87]。IC在多处应用了阈值签名。假设子网中的节点副本数量为,故障节点数量上限为。
- 共识层使用的阈值签名来实现随机信标(详见章节5.5)。
- 执行层使用的阈值签名来实现随机磁带,用于向容器提供不可预测的伪随机数(详见章节7.1)。
- 执行层使用的阈值签名来认证复制状态。这既用于验证子网的输出(详见章节6.1),也用于实现IC链演进技术中的快速转发功能。(详见章节8.2)
对于前两个应用(随机信标和随机磁带),阈值签名必须是唯一的,即给定公钥和消息,仅有一个有效签名。因为我们使用签名作为随机数生成器的种子,所有计算该阈值签名的节点副本必须对相同的种子达成共识。
3.1 BLS阈值签名
我们基于BLS签名方案实现了阈值签名[BLS01],使得调整阈值设定十分简单。
普通的BLS签名方案(即非阈值)利用两个质数阶均为的群和。我们假设通过基准点生成,通过基准点生成。我们同样假设一个哈希函数可以将其输入映射到(一个随机预言机模型)。签名私钥元素,公共验证密钥:= 。
非阈值的设定下,为对消息签名,签名人计算,然后计算签名:= 。为验证签名是否有效,必须检验是否等于。为了高效地执行检验,BLS方案在群和上使用了配对的概念,这是一种特殊的代数工具,当和是特殊类型的椭圆曲线时可用。我们无法在这里详细介绍配对和椭圆曲线。更多细节详见[BLS01]。BLS签名具有签名唯一这一良好的特性(如上所述)。
在的阈值设定下,我们有个节点副本,其中任意个都可以用于生成消息的签名。更具体来看,每个节点副本私下持有签名密钥的一个片段,而群元素:=公开可用。密钥片段是的秘密共享(详见章节3.4)。
给定消息,节点副本可以生成签名片段
与之前一样,。为了验证这样的签名片段是否有效,必须检验是否等于。如上所述,这可以通过配对来完成—事实上,这和用公钥验证普通BLS签名有效性完全一样。
这一阈值签名方案满足如下的重构特性:
给定消息的任意个有效签名片段的集合(由不同的节点副本提供),我们可以高效得计算出公共验证密钥下,消息m的有效BLS签名。
事实上,可以按如下公式计算
其中,可由签名该消息m的t个节点副本的索引,高效地计算出来。
在的合理难度假设下,将建模成随机预言机,这一方案可以满足如下的安全性:
假设最多有个节点副本被敌对方破坏。它也无法计算出消息的有效签名,除非他获取了至少个诚实节点副本对该消息的签名片段。
3.2 分布式密钥分发
为了实现BLS阈值签名,我们需要一种分发签名私钥给节点副本的方法。一种实现方法是让一个可信方直接计算所有这些私钥片段并分发给所有的节点副本。不幸的是,这可能会造成单点故障。相反,我们使用了分布式密钥生成(以下简称DKG)协议,它本质上允许节点副本在安全的分布式协议下,执行此类可信方的逻辑。
我们概述了当前实现的协议的顶层思想。推荐读者阅读[Gro21]了解更多细节。我们使用的DKG本质上是非交互式的。它有两个基本组成部分:
- 公开可验证秘密共享(以下简称PVSS)方案,和
- 共识协议。
尽管任何共识协议都适用,但毫无疑问我们使用了第5章(也可见第八章)中的协议。
3.3 假设
所做的基本假设和[第一章](#1 引言)中所概述的一致:
- 异步通信,和
- 。
我们仅仅(在章节5.1中)间接地使用了部分同步假设,来确保共识协议的活性。
对于一个t/n的阈值签名方案,我们还假设
这(除了其他方面外)确保了(1)故障节点副本们无法独立地签名,和(2)诚实的节点副本们可以独立地签名。
我们还假设每个节点副本和一些公钥相关联,其中每个节点持有这些公钥的对应私钥。一个公钥是签名密钥(同章节5.4中一样)。另一个公钥是公共加密密钥,用于实现PVSS方案的特殊公钥加密方案(详细方案如下)。
3.4 PVSS方案
如上所述,假设通过基准点生成的质数阶为的群。假设是私钥。回想一下,阈值结构为下,密钥的Shamir密钥共享是向量,其中
而
是次数小于的多项式,其中。该类密钥共享方案的关键属性是
- 根据个的集合,我们可以(多项式插值)有效地计算密钥,和
- 如果从中一致且独立得抽取,任意少于个元素的集合都无法披露密钥的任何信息。
在更高层面上,PVSS方案允许节点副本,在此称为dealer,进行密钥共享并计算称为dealing的对象,其中包括
- 群元素向量,其中对于,
- 密文向量,其中是的公共验证密钥下对的加密,
- 非交互式的零知识证明,证明每个节点副本确实加密了密钥片段—更准确地说,每个密文解密的值满足
我们注意到,为了确保DKG协议的整体安全性,PVSS方案必须提供适当级别的所选密文安全性。具体来说,dealer必须将其身份作为关联数据嵌入dealing,并且加密的共享片段必须要保持隐匿,即使是在选择密文攻击中,敌对方可以用与创建dealing无关的关联数据,解密任意dealing。
如果不考虑效率问题,实现PVSS方案很容易。方案中利用类似ElGamal的加密方案,对每个逐位加密,然后对公式(2)使用标准的非交互式零知识证明,该证明基于对相应的Sigma协议(详见[CDS94])应用标准的Fiat-Shamir转换(详见[FS86])实现。尽管这产生了一个多项式时间的方案,但是并不实用。然而,有很多可能的方法来优化这个类型的方案。关于IC中使用的高度优化的PVSS方案,详见[Gro21]。
3.5 基础DKG协议
使用PVSS方案和共识协议,基础的DKG协议十分简单。
每个节点副本向其他节点副本广播关于随机密钥的已签名dealing。
这样的已签名dealing包括一个dealing主体,dealer身份以及dealer公钥下对该dealing的签名。
如果语法格式正确,签名和非交互式的零知识证明有效,那么这样的签名dealing是有效的。
利用共识协议,节点副本对的有效的已签名dealing集合达成共识。
假设集合中的第个dealing包含群元素向量和密文向量。
然后阈值签名方案的公共验证密钥是
注意,签名私钥被隐式定义
节点副本的签名私钥x的片段为
其中是的解密私钥下对的解密。
节点副本的公共验证密钥是
需要注意的是,密钥片段包含的阈值结构为的Shami密钥共享。因此,公式(1)中出现的只是拉格朗日插值系数。这证实了章节3.1中提到的重构特性。至于中章节3.1提及的安全性,可被如下证明,在建模成随机预言机的情况下,假设PVSS方案是安全的,群和(通过配对)满足one-more Diffie-Hellman的特定类型的难度假设,即不存在有效的对手方,有概率赢得下面的博弈:
挑战者随机选择和,将给到对手方和
对手方向挑战者发起一系列查询请求,每一个请求都是形式的向量,挑战者回应对应的
为结束这场博弈,对手方输出向量和群元素,并将赢得博弈如果
并且输出向量不是请求向量的线性组合。
尽管当的情况下,需要这类one-more Diffie-Hellman假设,但是当的情况下,可以采用较弱的假设(即所谓的co-CDH假设,普通BLS签名方案的安全性即基于此)。
3.6 再共享协议
基础DKG协议可以被很容易地修改,因此不需要创建一个新的随机密钥的共享,而是创建一个先前共享密钥的新随机共享。
- 修改基础协议的第1步,以便每个节点可以广播已有共享片段的已签名dealing
- 修改第2步,以便就个有效的已签名dealing集合达成共识。此外,每个dealing都经验证以确保是现有共享片段的dealing(这意味着在第个dealing中的值应当等于的旧值)。
- 第3步中,通过计算个拉格朗日插值系数的和(和乘积),等于新的(和)。
4 P2P层
P2P层的任务是在子网的节点副本中传递协议消息。这些协议消息包括
- 用于实现共识的消息,例如,区块提案(block proposals),公证(notarizations)等(详见[第5章](#5 共识层))
- 入口消息(详见[第6章](#6 消息路由层))
本质上,P2P协议提供的服务是一个“尽力而为(best effort)”的广播通道:
如果一个诚实节点副本广播一条消息,那么这条消息最终会被子网中的所有诚实节点副本接受到。
协议的设计目标包括以下内容::
- 有限资源. 所有的算法都在有限的资源(内存,带宽,CPU)下运转。
- 优先级. 根据特定的属性(例如类型,大小和轮次),不同的消息将按照不同的优先级进行排序。并且这些优先级的规则可能随着时间将会改变。
- 高效 高吞吐量比低延迟更重要。
- 抗DOS/SPAM. 故障节点将不会影响诚实节点副本间的相互通信
注意到,在共识协议中,一些消息,尤其是区块提案(会非常大),将被所有节点副本反复广播。这对确保协议的正确运作是必须的。但是,如果单纯这样实现,将会是巨大的资源浪费。为了避免节点副本广播相同的消息,P2P层使用了公告-请求-传递的机制。它不会直接传递(大)消息,而是广播该消息的(小)公告:如果节点副本收到这样的公告并且没有收到过对应的消息,将认定该消息是重要的,节点副本将请求该消息的传递。这个策略以更高延迟的代价,降低了带宽使用。对于小消息而言,牺牲延迟追求带宽是不值得的,可以直接发送消息而不是公告。
对于相对较小的子网而言,希望广播消息的节点副本,会将公告发送至子网中的所有节点副本。对于较大的子网,公告-请求-传递机制可以在一个覆盖网络(overlay network)上运行。覆盖网络是一个连接的无向图,子网内的节点副本组成其顶点。如果图中有一条边连接两个节点副本,那他们是对等节点(peers),节点副本仅和它的对等节点通信。因此,当节点副本希望广播消息时,他将该消息的公告发送给它的对等节点。这些对等节点在收到公告后,可能会请求消息的传递,如果满足特定条件,这些对等节点会将该消息的公告发送给他们的对等节点。这本质上是一个gossip network。这个策略用比先前更高的延迟代价,再次降低了带宽使用。
5 共识层
IC共识层的任务是对输入消息进行排序,以确保所有的节点副本按照相同的顺序处理输入消息。 现在已有很多文献中的协议是为了解决这一问题。其中IC使用了一种新的共识协议,将在这一章进行简明扼要的阐述。更多的细节,参考[CDH+21] (特别是该论文中的 Protocol ICC1).
任何安全的共识协议应当确保以下两种属性,(粗略地)表述为:
- 安全性:全部节点副本事实上同意相同的输入顺序
- 活性:全部节点副本都应取得持续的进展
该论文[CDH+21] 证实了IC共识协议同时满足以上两种属性。
IC的共识协议在设计上:
- 极其简单,且
- 健壮的:当存在部分恶意节点副本时,性能也能优雅地下降。
5.1 假设
如引言所述,我们假设
- 一个子网包含个节点副本,和
- 其中最多的节点副本存在故障
故障节点副本可能表现出任意恶意(即拜占庭)的行为。
我们假设通信为异步且不存在对节点副本间消息延迟的先验限制。事实上,消息传递的调度可能完全受对手方控制。在此弱通信假设下,IC共识协议可以确保安全性。但是为确保活性,我们需要假设一定形式的部分同步,这(大体上)意味着网络在较短的时间间隔内保持周期性的同步。在此同步时间间隔内,所有未传输信息将在固定的时间限制内完成传递。时间限制不需要事先知晓(协议会初始化合理的限制,但动态地调节该值,且当时间限制过小时提高限制值)。无论我们假设网络为异步还是部分同步,我们都假设诚实的节点副本发送给另一个节点副本的消息最终都将被递送。
5.2 协议概述
像许多的共识协议一样,IC共识协议是基于区块链的。伴随着协议的推进,以创世区块(genesis block)为根节点的区块树将不断生长。每一个非创世区块都包含一个荷载(payload),由一系列输入和父区块的哈希组成。诚实节点副本对这个区块树有一致的视角:尽管每个节点副本可能对这个区块树有不同的局部视角,但是所有的节点副本看到的都是这一相同的区块树。此外,伴随着协议的推进,区块树中总会有一条最终确认区块的路径。同样地,诚实节点副本对这一路径有一致的视角:尽管每个节点副本可能对这条路径有不同的局部视角,但是所有的节点副本看到的都是这一相同的路径。沿着这条路径的区块的荷载中的输入,是已经排序好的输入并将由IC的执行层进行处理(详见第7章)。
IC的共识协议按照轮次进行处理。在轮次中,一个或多个块高的区块被添加到区块树中。也就是说,在轮次添加的区块,距离根节点的距离都是。在每一轮中,将通过伪随机过程给每一个节点副本分配一个唯一的排位,范围是的整数。这一伪随机过程使用了随机信标(Random Beacon)(详见如下章节5.5)来实现。排位最低的节点副本是该轮次的主节点。当主节点是诚实的并且网络同步时,主节点会提议一个新区块,并加入到区块树中;此外,这将会是该轮次唯一添加到区块树中的区块,并延伸最终确认的路径。如果主节点不诚实或者网络不同步状态,其他排位更高的节点副本也可以提议新区块,并将其添加到区块树中。在任何情况下,协议逻辑给予主节点提议的区块最高优先级,并且某个或某些区块会在该轮次被加入到区块树中。即使协议在没有延伸最终确认路径的情形下继续执行,区块树的高度也会在每轮继续增长,这样最终确认路径会在轮次继续延伸,使其长度达到。上述做法下,即使故障节点副本或不可预测的高网络延迟导致延迟增加,整体协议的吞吐量大体上依旧维持稳定。
5.3 额外特性
一个由IC共识协议带来的额外属性(如同 PBFT [CL99]和HotStuff [AMN+20], 而不像别的协议, 诸如Tendermint [BKM18])是乐观响应[PS18]。这意味着,当主节点诚实时,协议会以实际网络延迟而非网络延迟上限继续执行。
我们注意到IC共识协议的简洁设计也确保了当拜占庭故障实际发生时,IC的性能也能相当优雅的下降。如同[[CWA+09]](#CWA09)中指出的,共识目前大量的工作都专注于没有故障的“乐观情况”下的性能提升,这导致协议变得危险且脆弱,以至于故障真的发生时协议无法使用。例如[CWA+09]所述,现有PBFT吞吐量在特定(极其简单)的拜占庭行为下会下降至0。该论文[CWA+09]倡导健壮的共识,意味着部分牺牲最优状态的最佳性能,以确保部分恶意节点(但依然假设网络为同步)时的合理性能。IC的共识协议在其[CWA+09]的讨论下,确实是健壮的:当任意轮次中主节点发生故障时(发生概率小于),协议将尽可能有效得允许别的节点副本接替成为主节点,使得协议能够及时推进至下一轮。
5.4 公钥
为实现该协议,每个节点副本都关联了一个用于BLS签名的公钥,并且每个节点副本都拥有对应的签名私钥。节点副本与公钥的关联关系可从NNS维护的注册表中获得。这些BLS签名将用于验证节点副本发送的消息。
协议同时使用BLS签名[BGLS03]的聚合签名的特性,该特性允许同一条消息的多个签名聚合为一个压缩的多签。协议将在公证(notarization) (详见章节5.7)and 最终确认(finalizations)(详见 章节 5.8)时,使用特定格式消息上的签名聚合而成的多签。
5.5 随机信标
除了上述的BLS签名与多签外,协议使用BLS阈值签名方案来实现上文提及的随机信标。块高的随机信标是对块高中特定消息的阈值为的签名。协议的每一轮中,每个节点副本广播其下一轮中信标的片段,这样当下一轮开始时,每一个节点副本都有足够的片段来重构此轮需要的信标。如上所述,在轮次,块高的随机信标被用来给每个节点副本分配伪随机排位。因为阈值签名的安全特性,对手方将无法提前一轮以上去预测节点副本的排名,因此这些排位拥有有效的随机性。BLS阈值签名细节详见[第3章](#3 链钥密码学I:阈值签名)。
5.6 区块生成
每一个节点副本可能在不同的时间节点充当区块生成者的角色。作为轮次的区块生成者,此节点副本提议一个块高的区块,作为区块树中块高的区块的子区块。为此,区块生成者首先合并一个包含已知所有输入的荷载(但并不包括截至之前的已有区块中的荷载)。区块中包含:
荷载,
的哈希,
区块生成者的排位,
区块的高度 。
当生成区块后,区块生成者会生成一份区块提案,包含:
区块,
区块生成者的身份,以及
区块生成者对于区块的签名。
区块生成者将其区块提案广播给其他所有的节点副本。
5.7 公证
当区块完成公证时,该区块才会被纳入区块树中。为使区块实现公证,必须个不同的节点副本支持该公证。
给定提议的块高的区块,节点副本会根据上述的区块组成来判断该区块提案是否有效。具体来说,应该包括区块树中块高为 ' 的区块 B' 的哈希(即已被公证)。此外,的荷载必须满足特定的条件(尤其是荷载中的所有输入必须满足各种通常与共识协议无关的限制)。同时,区块生成者的节点副本排名(记录于区块B),必须和随机信标在轮中分配给提议区块的节点副本的排名(记录在区块提案中)相匹配。
如果该区块有效且满足别的特定限制,节点副本将广播区块的公证片段以支持该区块的公证,公证片段 组成如下:
- 区块的哈希,
- 区块 的块高,
- 支持公证的节点副本的身份,以及
- 支持公证的节点副本,对包含区块哈希和块高 的消息的签名。
任意个公证片段的集合可被聚合在一起形成区块的公证,组成如下:
- 区块的哈希,
- 区块 的块高,
- 个支持公证的节点副本的身份集合
- 一条消息上的的签名聚合,包含的哈希以及块高
一旦节点副本获得了一个公证后块高的区块,它就会结束轮次并随即不支持其它块高的区块,同时转发该公证给其他所有的节点副本。注意该节点副本有两种方式获得公证,(1)接收自其它节点副本 或(2)聚合收到的个公证片段。
增长不变性(Growth Invariant)表明每个诚实节点副本最终都会完成每一轮并且开始下一轮次,因此经过公证的区块树会持续增长(该性质只需假设异步下的最终递送,而不需要部分同步)。我们随后证明了增长不变性(详见章节5.11.4)。
5.8 最终确认
在给定块高可能存在多个经公证的区块,但是一旦一个区块被最终确认,则我们可以确定在块高没有其它经公证的区块。让我们称之为安全不变性(safety invariant)。
一个区块要实现最终确认,必须有个不同的节点副本支持其最终确认。回想一下,当节点副本获得一个经公证的块高的区块时,轮次结束。此时,该节点副本将检查其是否支持过除区块以外的其他块高的区块的公证。如果没有,则该节点副本会广播区块的最终确认片段以支持其最终确认。最终确认片段的格式与公证片段的格式完全相同(但是通过标签来以防止混淆)。任何个区块的最终确认片段的集合都可以被聚合一个区块的最终确认,其拥有与公证相同的格式(同样通过标签区分)。任何收到最终确认区块的节点副本,都将广播最终确认给其它的节点副本。
我们在下面证明了安全不变性(详见章节5.11.5)。 安全不变性的一个结果是,假设两个区块和都被最终确认,其中的高度为,的高度为。则安全不变性意味着,以区块为结尾的经公证区块树的路径,是以区块为结尾的经公证区块树的前缀(如果不是,则在块高将会有两个经公证的区块,这违背了最终确认不变性)。因此,任何时候当一个节点副本看见最终确认的区块,它会视区块的所有前置区块为隐形得最终确认,同时又因为安全不变性,可以确保这些已经(显性得或隐形得)最终确认的区块安全属性,这意味着所有的节点副本都同意这些最终确认区块的排序。
5.9 延迟函数
该协议应用了两种延迟函数,与,他们控制着区块的生成与公证的节奏。这两个函数都映射提议区块的节点副本排名到一个非负的延迟,且假设每个函数都按单调增长,且对于所有,。这两个函数推荐的定义是和,其中是由一个诚实节点副本传递消息给另一个诚实节点的时间上限,而是一个防止协议运行过快的“调节器”。通过这些定义,在如下轮次中可确保活性 (1)主节点是诚实的(2)诚信节点副本间的消息在时间内确实传递了。事实上,如果(1)和(2)在给定轮次种同时满足,则本轮主节点提议的区块会被最终确认。让我们把其称之为活性不变性(Liveness Invariant)。我们在下面证明了该特性(详见 章节 5.11.6)。
5.10 例子
图2展示了一颗区块树。每一个区块都被标记了块高()和区块生成者的排名,该图同时展示了区块树中的每一个区块经过了公证,并以符号标记。这意味着区块树中的每一个经公证的区块至少得到了个不同节点副本的支持。可以看到,在指定的块高可以存在不止一个经公证的区块。例如,在块高32上,我们可以看到两个经公证的区块,分别由排名第1和第2的区块生成者提议。同样的事情在块高34上也发生了。我们也可以看到块高36的区块明确得被最终确认,正如符号所标识的。这意味着个不同个节点副本支持了该区块的最终确认,意味着这些节点副本(或至少其中的诚实节点副本)不支持其它任何区块的公证。该区块的所有前置区块,即图中阴影灰色的区块,都被认为得到了隐性的最终确认。
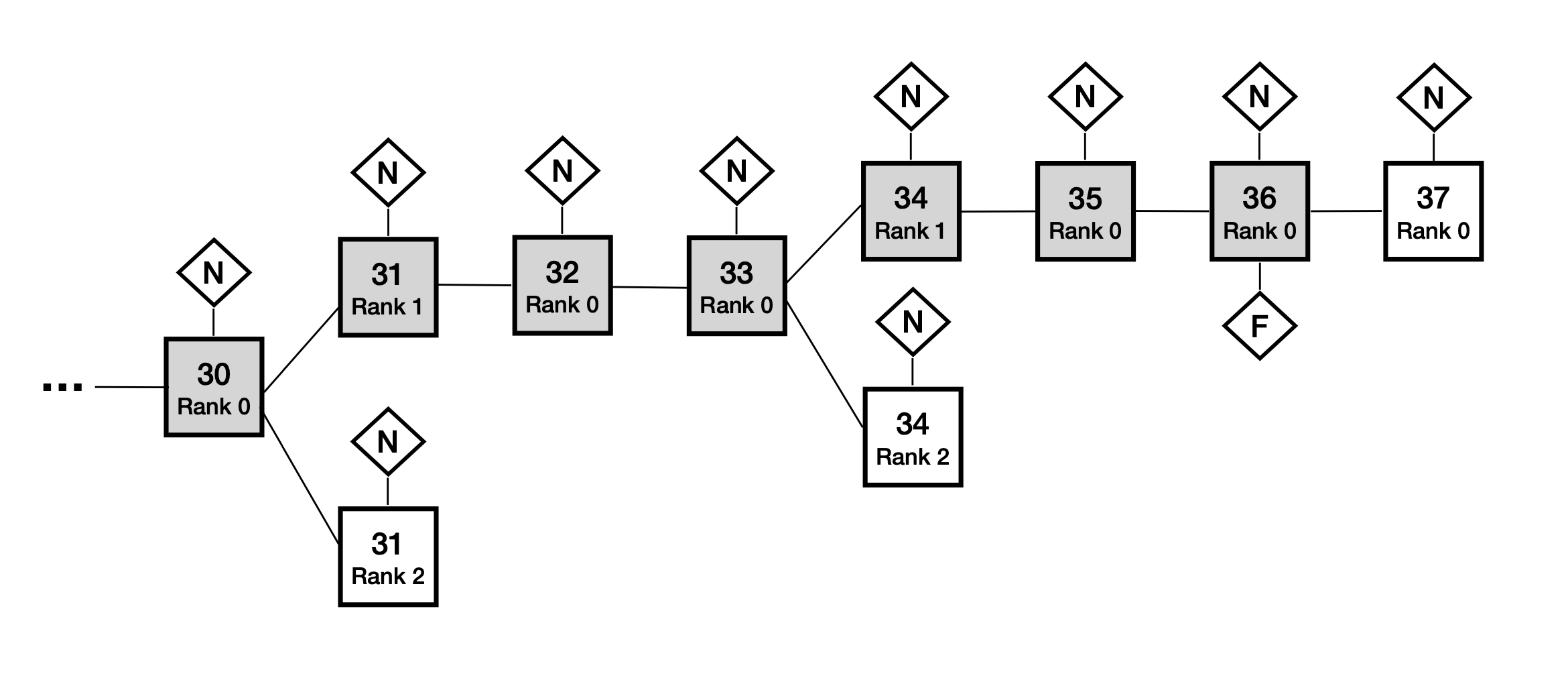
5.11 组合阐述
我们现在更详细地描述该协议的工作原理;具体来说,我们将更准确地描述节点副本何时会提议一个块及何时支持区块的公证。给定的节点副本将记录其进入轮次的时间,此时其已经获得(1)块高的公证(2)轮次的随机信标。因为轮次的随机信标已经决定,可以判定轮次中自己的排名以及其它节点副本的排名。
5.11.1 随机信标详述
一旦节点副本接受到了轮次的随机信标或是足够的片段以构建轮次的随机信标,它将在轮次中继该随机信标给所有的其它节点副本。一旦一个节点副本进入了轮次,它将生成并广播它在轮次+1中随机信标的片段。
5.11.2 区块生成详述
节点副本只会在如下情况时提议区块(1)自轮次开始已经过去至少个时间单位(2)无有效的更低排名的区块被发现。
注意因为当进入轮次时,确保了拥有经公证的块高的区块,它可将其提议的区块作为该经公证的区块的子区块(或是其拥有的其它任意经公证的块高区块)。同时注意当广播其区块的提案时,它必须确保已经将区块的父区块的公证传递给所有节点副本。
假使节点副本看见了一个来自排名的节点副本P的有效区块提案,且(1)自轮次开始已经过去至少个时间单位(2)当前没有看见没有其它更低排名的区块。则在该时间点,如果该区块提案尚未被递送,将传递该区块提案(附带提议区块的父区块公证)。
5.11.3 公证详述
节点副本会支持由排名的节点副本提出的有效区块的公证,当(1)自轮次开始已经过去至少个时间单位(2)当前没有其它排名小于的区块被发现。
5.11.4 增长不变性(Growth Invariant)证明
增长不变性表明了,每个诚实节点副本最终都会完成当下轮次并开始下一轮次。假设所有诚实节点副本都开始了轮次,假定为轮次排名最低的节点副本的排名,最终会(1)自己提议区块 或(2)转发一个由更低排名的节点副本提议的有效区块。在任意一种情况下,某个区块都必将被所有诚信节点副本支持,这意味着某个区块将会被公证且所有诚实节点副本将会完成轮次。所有诚实节点副本也将会接收到构建轮的随机信标所需的片段,并开始轮次。
5.11.5 安全不变性(Safety Invariant)证明
安全不变性阐述了给定轮次中如果一个区块被最终确认,则没有其它区块会在该轮被公证。安全不变性的证明如下:
- 假设故障节点副本的数量恰好为。
- 如果区块被最终确认,则其最终确认必须被由个诚实节点副本组成的集合支持(基于聚合签名的安全性)。
- 假定(相矛盾的情况下)另一个区块且被公证,则该公证必须被由至少个诚实节点副本组成的集合支持(同样基于聚合签名的安全性)。
- 集合与集合是不相交的(基于最终确认的逻辑)。
- 因此 且意味着为悖论。
5.11.6 活性不变性(Liveness Invariant)证明
我们认为,如果所有诚实节点副本间在时间点时或之前发送的的消息,都会在前到达目的地,则该网络在此时为-同步。
活性不变性可表述如下。假设 ,且假定在给定轮次,我们有
- 轮次的主节点副本为诚实的,
- 第一个进入轮次的诚实节点同样如此,和
- 该网络在以及时,为-同步。
则在提议的区块在轮次将被最终确认。
下面为活性不变性的证明:
- 在部分同步下,时所有的诚实节点副本都会在时间前进入轮(节点结束轮次的公证以及轮次的随机信标,都会这之前到达所有诚实节点副本)。
- 轮次的主节点在时将提议区块,且同样基于部分同步,该区块提案将在前传递至其它所有节点副本。
- 因为,协议的该逻辑确保了每个诚实节点副本仅支持区块而非其他区块的公证,因此*被公证和最终确认。
5.12 其他问题
5.12.1 增长延迟(Growth Latency)
部分同步假设下,我们可以构想并证明增长不变性的量化版本。简单来说,假设延迟函数按照上文推荐的定义为:和,且进一步假设。假设在时,任何节点副本进入的最高轮次为。令 为排名最低的诚实节点在轮的排名。最终,假设该网络在的时间区间内为-同步。那么所有诚实节点副本都会在时间前开启轮次。
5.12.2 本地化调整的延迟函数
当一个节点副本在多个轮次后都没有见到最终确认的区块,它将开始增加其用于公证的延迟函数。节点副本间无需同意这些本地化调整的公证延迟函数。
另外,当节点副本不直接调整他们的延迟函数时,我们可以通过本地化调整这两个延迟函数,数学建模本地的时钟偏移。
因此,会存在以节点副本和轮次为参数的许多延迟函数。活性所需的关键条件变成,且最大和最小值来自给定轮次的所有诚实节点副本。因此,如果一定轮次的最终确认失败,所有的诚实节点副本都会最终提升他们的公证延迟,直到条件满足,接着最终确认将恢复。如果一些诚实节点副本的公证延迟函数比其他节点副本增长更多,对活性而言不会有影响(但可能会对增长延迟有影响)。
5.12.3 公平性
在共识协议中另一个重要的属性是公平性。相较于给出一个通用的定义,我们发现活性不变性也暗示着一个有用的公平性属性。回想一下,活性不变性本质上意味着在任何一轮中,当主节点为诚实且网络为同步时,则主节点提议的区块也将被最终确认。在此情况的轮次中,诚实的主节点事实上确保了,它区块的荷载中包含它所知道的所有输入(取决于荷载大小的模块限制)。因此大体上来说,任何广播给足够节点副本的输入,大概率都将在合理时间内被包含进最终确认的区块中。
6 消息路由层
如同章节 1.7中讨论的,IC中的基础计算单元称为容器,可以粗略的等同于进程的概念,其同时包含了一个程序和它的状态。IC提供了容器中执行程序的运行时环境并使其能够于其他容器和外部用户通信(通过消息传递)。
共识层(见[第5章](#5. 共识层))将输入打包进区块的荷载中,并随着区块被最终确认,相应的荷载会被传递给消息路由层并由执行环境处理。执行层将随之更新复制状态机中相应容器中的状态,并将输出交由消息路由层处理
有必要区分两种输入类型:
入口消息:来自外部用户的消息
跨子网消息:来自其他子网的容器的消息
我们同样可以区分两种输出类型:
入口消息响应:对于入口消息的响应(可被外部用户取回)
跨子网消息:传输给其他子网容器的消息
当收到来自共识的负载后,这些负载中的输入会被置入不同的输入队列。对于一个子网下的每一个容器 ,都存在多个输入队列:用于发给的的入口消息,用于和通信的每一个别的容器'(如果和不在同一个子网,将会是跨子网消息)。如下详述,在每一轮中,执行层都会消耗这些队列中的一些输入,更新相应容器中的复制状态,并将输出置于不同的输出队列中。对于一个子网下的每一个容器,都存在多个输出队列:对于每一个与通信的容器,都有其各自的队列(如果和不在同一个子网,将会是跨子网消息)。消息的路由层将取得消息队列中的消息并置入子网间数据流,以被跨子网传输协议处理 ,该协议的工作是将这些消息实际传输到其他子网。
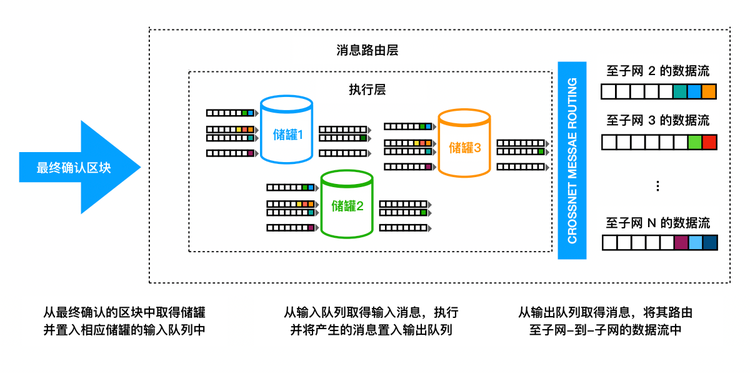
除了这些输出队列外,同时存在一种入口历史的数据结构。一旦一条入口消息已被容器处理,对该条入口消息的响应将被记录在该数据结构中。此刻,提供该条入口消息的外部用户将能够获取相关的响应。(注意入口历史并不保留所有入口消息的完整历史)。
我们也应提及除了跨子网消息外,也存在着子网内消息(intra- subnet messages),这些是同一子网下由一个容器发送给另一容器的消息。消息路由层会将这类消息由输出队列直接移至对应的输入队列中。
图3展示了消息路由层以及执行层的基础功能。
需要注意的是,节点副本的状态包括容器的状态以及“系统状态”。“系统状态”包括上述提及的队列,数据流以及入口历史的数据结构。因此,消息路由层和执行层同时参与更新和维护子网的副本状态。此状态应全部在完全确定性的原则下被更新,这样所有的节点都会维护完全相同的状态。
另外需要注意的是,共识层解耦于消息路由层以及执行层,也就是说传入荷载之前,共识区块链中的任何分叉都已经被解决了。事实上,共识层允许提前运行,并不需要和消息路由层保持完全一致的进度。
6.1 每轮认证状态(Per-round certified state)
在每一轮,一个子网下的某些状态会被认证。每轮认证状态通过链钥密码学(详见章节1.6)进行验证,具体使用了[第3章](#3 链钥密码学I:阈值签名)提及的的阈值签名。细节上,给定轮次下当每个副本生成了每轮认证状态,副本将生成相应阈值签名的片段并将其广播给其子网下的所有其他节点副本。一旦收集了个片段,每个节点副本就可以构建出最终的阈值签名,该签名作为该轮次每轮认证状态的证书。需要注意的是,签名前每轮认证状态会经哈希计算为默克尔树(Merkle Tree )[Mer87]。 给定轮次的每轮认证状态包含
- 最近加入子网间数据流的跨子网消息;
- 其他元数据,包括入口历史的数据结构;
- 来自前一轮的每轮认证状态的默克尔树的根节点哈希。
请注意每轮认证状态并不包括一个子网的完整副本状态,因为这么做整体上状态将非常庞大,而且在每轮认证全部状态也并不实际5。
图4展示了每轮认证状态是如何被组织入树中的。该树的第一个分支存储了多种关于每一个容器的元数据(但不是容器的完整副本状态)。第二个分支储存了入口历史的数据结构。第三个分支储存了关于子网间数据流的信息,包括了对每个数据流新加入的跨子网消息的“视图”。其他的分支存储了其他类型的元数据,这里不做讨论。该树状结构之后可被哈希计算为一棵默克尔树,其本质上拥有与该树相同的尺寸和形状。
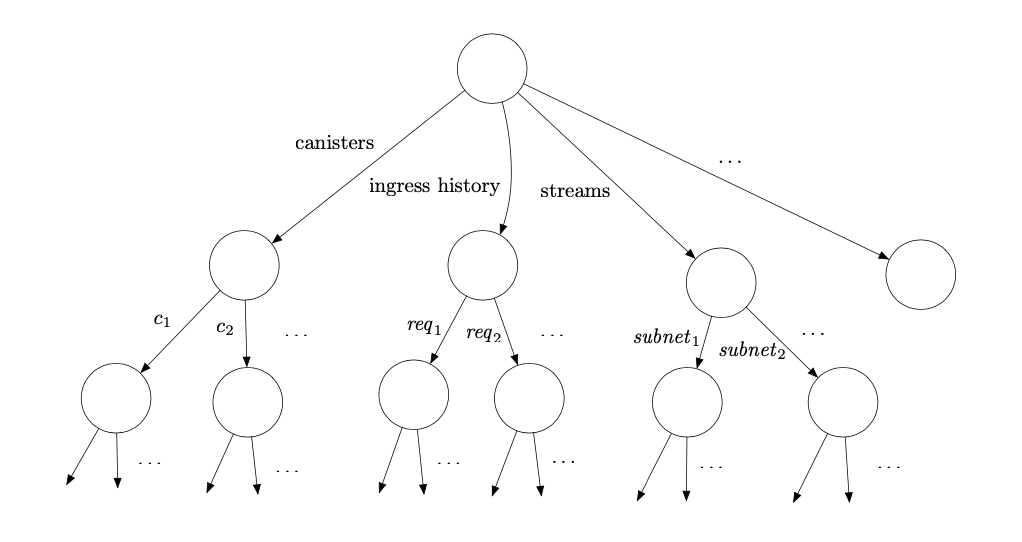
每轮认证状态在IC中有一下用例:
输出验证。跨子网消息和入口消息响应可以利用每轮认证状态进行验证。使用默克尔树的结构,一个单独的输出(跨子网消息或是入口消息响应)可以被任一方通过提供根节点的阈值签名来验证,以及默克尔树中从根节点至叶节点的路径(以及相邻的)的哈希值。因此,验证一个单独输出的所需的哈希值数量与默克尔树的深度成比例,即使哈希树的尺寸非常大,该数值也通常非常小。因此,单个阈值签名可被有效的用于验证许多单独的输出。
防止并识别非确定性。共识确保了每个节点按相同的顺序下处理输入。因为每个节点副本都确定性处理这些输入,每个节点副本都应取得相同的状态。但是,IC在设计上额外增加了一层健壮性来发现并阻止任何(意外的)非确定性计算,如果其真的发生。其中每轮认证状态是该机制中的一部分,因为我们使用了的阈值签名来认证,且,所以仅有单个状态序列可被认证。
要理解状态成链为何如此重要,我们考虑如下的例子。假设我们有四个节点副本,且其中一个节点副本为恶意节点。起始状态都相同。
在轮次1,由于非确定性计算,均开始计算一条消息以发送至子网A,而则计算以发送至子网A。
在轮次2,均开始计算消息以发送至子网,而则计算消息以发送至子网
在轮次3,均开始计算消息m3以发送至子网C,而P2则计算消息以发送至子网
如下表所示:
我们假设节点各自执行有效序列的计算,但是因为非确定性,这些序列并不相同。(即使不应当存在任何的非确定性,我们在这个例子中依然假设其存在。)
现在假设我们没有将这些状态成链。因为为恶意且可能签名任何内容,它可以在轮次1的状态中创建一个申明“”的的阈值签名,类似得在轮次2的状态中申明”“,并在轮次3状态中申明“”,尽管对应的序列
可能不与任何有效的序列兼容。更糟糕的是,此无效的计算序列可能导致了其他子网的状态不一致。
通过成链,我们确保了即使存在一定程度的非确定性,任何经认证状态的序列都对应了一些由诚实节点执行的有效序列。
- 与共识协作。每轮认证状态也被用于与执行层和共识层协作,有如下两种方式:
- 共识降速(Consensus throttling)。每个节点都会跟踪存在认证状态的最新轮次—这被称之为认证高度。它也将跟踪存在经公证区块的最新轮次—这被称之为公证高度。如果公证高度明显大于认证高度,这是执行延迟于共识的信号,则共识需被降速。该延迟可能由非确定性计算或者由协议不同层中的性能不匹配导致。共识将通过章节5.9中讨论的延迟函数进行降速—具体来说,每一个节点都会增加其调节器的数值,作为公证高度与认证高度增长的时间间隔(这里用了章节5.12.2中提及的“本地化调整的延迟函数”的概念)。
- 特定状态的荷载有效性验证(State-specific payload validation)。如章节5.7所述,负载中的输入必须通过某些有效性检查。事实上,这些有效性检查可能取决于该状态的进度。我们略过的一个细节是,每个区块都包含一个轮次数,这些有效性检查应当考虑该轮次的验证后状态。一个需要执行验证的节点需要等待该轮次的状态被认证,然后使用该轮经认证的状态来进行验证。这么做确保了即使存在非确定性计算,所有的节点都在进行相同的有效性测试(否则共识可能会停滞)。
6.2 查询调用和更新调用
正如我们之前所述,所有的入口消息必须经过共识,才能被子网的所有节点副本按相同的顺序进行处理。但是,针对那些处理时不会变更状态的入口消息,可以进行一项重要的优化。他们被称为查询调用—而相对的其他入口消息,被称为更新调用。查询调用被允许进行只读或是可能改变容器状态的计算,但是任何对节点副本状态的更新都不会被提交给复制状态。正因如此,查询调用可以被单个节点副本直接处理而不需要经过共识,这极大的降低了从查询调用获得响应的延迟。
需要注意的是,查询调用的响应不会记录在入口历史的数据结构中,因此也不可以用之前的每轮认证状态进行验证。但是,我们提供了一种单独的用于验证该类响应的机制:认证变量。作为每轮认证状态中的一部分,每个子网下的容器都被分配了一小段字节,这便是该容器的认证变量,其值可通过更新调用进行更新,也可被每轮认证状态机制来进行验证。另外,容器也可使用其认证变量来存储默克尔树的的根节点。通过这种方式,只要查询调用的响应是该容器中以认证变量为根的默克尔树的叶节点,即可被验证。
6.3 外部用户验证
入口消息和跨子网消息的一个主要区别在于用于验证消息的机制。我们已经看到(详见章节6.1),聚合签名如何被用于验证跨子网消息。NNS的注册表(见章节1.5)持有用于验证跨子网消息的阈值签名的验证公钥。
IC中没有外部用户的中央注册表。相反,外部用户通过一串公钥哈希作为用户标识(又称principal)来向容器来标识自己。用户自己持有对应的签名密钥,用来签署入口消息。签名和公钥会随着入口消息一起发送。IC将自动验证签名并传递用户标识给到对应的容器。随后该容器根据用户标识和入口消息中指定操作的其他参数,批准请求的操作。
新用户在首次与IC交互时会生成一对密钥对并从公钥中衍生出他们的用户标识。老用户根据存储在用户代理中的私钥完成验证。用户还可以用签名委托的方式,将多个密钥对关联到一个用户身份上。该特性非常有用,因为它允许了一个用户在多个设备上通过相同的用户身份证明来访问IC。
7 执行层
执行环境每次处理一条输入,该输入取自输入队列中并被导向容器。取决于该条输入以及容器的状态,执行环境更新容器的状态并可以额外添加消息至输出队列,并且更新入口历史(可能连同此前入口消息的响应)。 在给定轮次,执行环境将处理多条输入。调度器(Scheduler)会判断哪些输入按何种顺序下将在指定轮次中执行。我们这里不深入讨论过多调度器的细节,而是着重强调一些目标:
- 它必须是确定性的,即仅仅取决于给定数据;
- 它应当公平的在容器间分布工作量(但对吞吐而不是延迟进行优化)。
- 每轮的完成的工作量使用cycles(详见章节1.8)为计量单位,且应当接近一些预先设定的数量。
另一个执行环境必须处理的任务是,当某子网的容器的生产跨子网消息的速度,比其他子网能够消耗的速度更快的情况。针对该情况,我们实现了一种自我监管的机制用于给生产容器降速。
运行环境还要处理许多其他的资源管理以及簿记任务,但是,所有这些任务都须确定地得到处理。
7.1 随机磁带
每个子网都拥有分布式伪随机生成器(以下简称PRG)的访问权限。如[第3章](#3 链钥密码学I:阈值签名)提及的,伪随机位可以从一个由的BLS阈值签名衍生而来,被称为随机磁带。共识协议的每一轮都有一个不同的随机磁带。虽然此BLS签名与共识中使用的随机信标的签名相似(详见章节5.5),其机制却略有不同。
在共识协议中,一旦块高的区块被最终确认,每个诚实节点将释放其在块高下随机磁带中的片段。此处隐藏两点含义:
- 在块高的区块被任何诚实节点副本最终确认前,块高的随机磁带是被确保为不可预测的。
- 在块高的区块被任何诚实节点副本确认时,该节点副本一般将拥有所有所需的片段以构建块高的随机磁带。
例如在轮次时,子网为获得二进制伪随机数,需要从执行层发起“系统调用”。当块高的随机磁带可用时,系统随后就会响应该请求。根据上述的特性(1),我们可以确保在请求发起时,被请求的二进制伪随机数是不可预测的。基于上述的特性(2),一般在下个区块被最终确认时,被请求的二进制伪随机数即可获取。事实上,在当前的实现中,在块高的区块被最终确认时,共识层(详见[章节5](#5 共识层))将会同时递交块高的区块(其荷载)以及的随机磁带来给消息路由层处理。
8 链钥密码学Ⅱ:链演进技术
如章节1.6.2所述,链钥密码学包括一系列复杂的技术,用于健壮和安全地持续维护基于区块链的复制状态机,合起来我们称之为链演进技术。每个子网在包含多轮(通常大约是几百轮)的时期(Epoch)内运行。链演技术实现了许多按时期定期执行的基本维护工作:垃圾回收,快速转发,子网成员变更,主动秘密再共享和协议升级。
链演进技术包含两个基本组成部分:摘要块(Summary Bblocks)和追赶包(Catch-Up Packages,以下简称CUPs)。
8.1 摘要块
每个时期的第一个区块是摘要块。摘要块包含特殊数据,用于管理不同阈值签名方案的密钥片段(详见[第3章](#3 链钥密码学I:阈值签名))。其中有两种阈值签名方案:
- 阈值结构为的方案中,每个时期生成一个新的签名密钥;
- 阈值结构为的方案中,每个时期重新共享一次签名密钥。
阈值低的方案用于随机信标和随机磁带,而阈值高的方案用于验证子网的复制状态。
回想一下,DKG协议(详见章节3.5)要求,对于每个签名密钥,有一个dealing的集合,而每个节点副本可以根据这组dealing,非交互式得获取它的签名密钥片段。
再回想一下,除了别的之外,NNS还维护着决定子网成员的注册表(详见章节1.5)。注册表(以及子网成员)会随时间改变。因此,子网必须在不同时间出于不同目的,对使用的注册表版本达共识。这一信息也存储在摘要块中。
时期 的摘要块包括如下数据字段。
。这个注册表版本将决定时期 中的共识委员会(consensus committee)—所有共识层的任务(生成区块,公证,最终确认)都由这个委员会执行。
。在每一轮共识中,区块生成者会将其知道的最新注册表版本(不得早于提议的区块的构建时间)包含在区块提案内。这确保了时期中的nextRegistryVersion是最新值。
时期 中的值设置为时期中的值。
。这个dealing集用于决定时期中签名消息的阈值签名密钥。
正如我们所看到的,时期 中的阈值签名委员会是时期中的共识委员会。
。这个字段收集和存储时期中收集到的dealing6。时期 中的的值将被设置为时期中的值(本身包含时期中收集到的dealing)。
。这个字段描述了时期中需要收集的dealing集的参数。时期 中,区块生成者会将经这些参数验证有效的dealing,放进提议的区块内。
Dealings的接受委员会基于时期的摘要块的。
对于低阈值的签名方案,时期中的交易委员会是时期中的共识委员会。
对于高阈值的签名方案,密钥片段的共享是基于时期中的。因此时期中的交易委员会是时期中的接受委员会,也是时期中的共识委员会。
还要注意的是,时期中的阈值签名委员会是时期中的接受委员会,其是时期中的共识委员会。
时期中的共识协议依赖于时期中的和 —具体来说,共识委员会本身基于,共识中的随机信标基于。此外,同其他区块一样,在时期开始的时候可能会有多个经过公证的摘要块,并且这种歧义需要在时期中经过共识来解决。这种看似循环的问题的解决办法是,保证时期开始时的摘要块,在时期开始前已经被最终确认,因为新的摘要块的相关值,是直接从老的摘要块复制而来。这实际上是一个隐含的同步假设,但它更是一个学术假设。事实上,因为章节5.12.2中讨论的确保活性的“共识降速(consensus throttling)”,也因为时期的长度很长,下面的情况本质上不可能发生:早在共识进展到时期结束之时,时期的摘要块没有被最终确认,公证延迟函数将增长到非常之大,因此最终确认需要的部分同步假设(实际上)肯定会(基本)满足7。
8.2 CUPs
在阐述CUP之前,我们首先需要指出随机信标的一个细节:每一轮的随机信标取决于前一轮的随机信标。它不是CUP的基本特性,但是影响了CUP的设计。
CUP是一种特殊的(不在区块链上的)消息,它(基本上)拥有一个节点副本在不知道先前时期任何信息下,在时期的起始点开始工作时所需的一切。它包含如下的数据字段:
- 整个复制状态的默克尔哈希树的根(与章节1.6中的每轮验证的部分状态不同)。
- 时期的摘要块。
- 时期第一轮的随机信标。
- 子网对上述字段的的阈值签名。
为生成给定时期的CUP,节点副本必须等到该时期的摘要块已经被最终确认,并且对应的每轮状态经过验证。如前所述,整个复制状态必须经哈希函数处理为一个默克尔树—尽管有很多技术用于加快这一过程,这个成本代价仍然非常大,这也是为什么每个时期仅处理一次。因为CUP仅包含这个默克尔树的根,因此我们使用了一个状态同步子协议,允许节点副本从对等节点中提取它所需要的任何状态—同样地,我们用了很多技术来加快这一过程,它的成本代价仍然很大。因为我们对CUP使用了高阈值签名,因此可以保证在任何时期只有一个有效的CUP,而且可以从很多对等节点中提取状态。同时,阈值签名方案的公钥保持一致,CUP可以在不知道当前子网的参与节点的情况下验证。
8.3 链演进技术实现
垃圾回收:因为CUP包含特定时期的信息,因此每个节点副本可以安全地清除该时期前所有已处理的输入,以及对这些输入排序的共识层消息。
快速转发:如果一个子网中的节点副本大幅落后于其同步节点(因为其宕机或是网络断连很长时间),或是一个新的节点副本被添加入子网,他们可以通过快速转发至最新时期的起始点,不需要运行共识协议并处理该点之前的所有输入。该节点副本可以通过获取最新CUP做到。利用从CUP中包含的摘要块和随机信标,以及来自其他节点副本的(还没有被清除的)共识消息,该节点副本可以从相应时期的起始点开始,向前运行共识协议。该节点也可以使用状态同步子协议来获取对应时期开始时的复制状态,这样它也可以开始处理共识层产生的输入。
图5描绘了快速转发。此处,我们假设需要一个需要追赶的节点副本处于时期起始点,(比方说)块高为101,有一个CUP。这个CUP包含了块高101的复制状态的默克尔树的根,块高101的摘要块(绿色标识)和块高101的随机信标。该节点会使用状态同步子协议,从它的对等节点中获取块高101的所有复制状态,并用CUP中的默克尔树来验证此状态。在获取到该状态后,节点副本可以参与到协议之中,从对等节点中获取块高102,103等等的区块(以及其他和共识相关的消息),并更新其复制状态的副本。如果其对等节点已经确认了更高高度的区块,该节点副本将尽快处理(以及公证和最终确认)这些从对等节点获取的已最终确认区块(以执行层所允许的最快速度)。
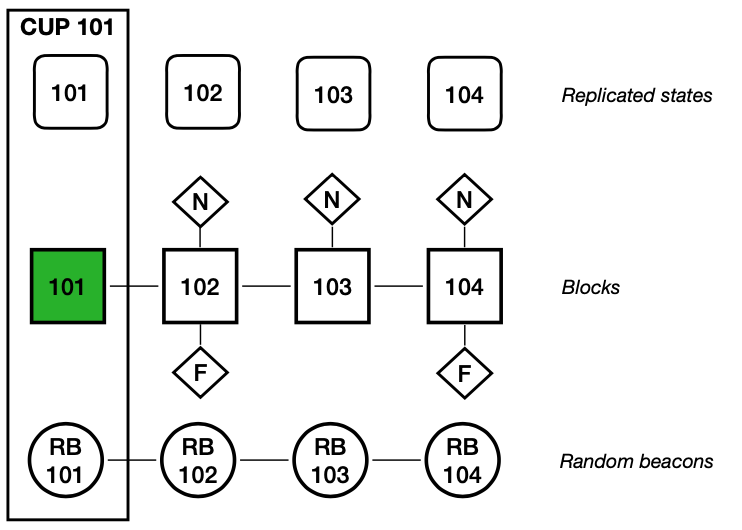
子网成员变更:我们已经讨论过特定时期内,如何使用摘要块来加密,使用哪个版本的注册表以及它如何决定子网成员,更具体来说,是各种任务的委员会成员。需要注意的是,即使一个节点副本从一个子网中移除,(如果可能的话)它应当额外履行一个时期的所分配到的委员会职责。
主动秘密再共享:我们已经讨论过了,如何使用摘要块生成和转发签名密钥。如有必要,需要的摘要块也可以从CUP中获取。
协议升级:CUP也可用于协议升级。协议升级由NNS发起(详见章节1.5)。不考虑所有细节,基本细节如下:
- 当需要安装新版本的协议时,时期开始时的摘要块会做出指示;
- 所有运行老版本协议的节点副本,将继续运行共识协议直到最终确认摘要块并创建对应的CUP;然而,他们只会创建空区块,并不会将任何荷载传递给消息路由层和执行层;
- 安装新版本的协议后,运行新版本共识协议的节点副本,将从上述的CUP开始继续运行完整的协议。
参考文献
[BGLS03] D. Boneh, C. Gentry, B. Lynn, and H. Shacham. Aggregate and Verifiably Encrypted Signatures from Bilinear Maps. In E. Biham, editor, Advances in Cryptology - EUROCRYPT 2003, International Conference on the Theory and Applications of Cryptographic Techniques, Warsaw, Poland, May 4-8, 2003, Proceedings, volume 2656 of Lecture Notes in Computer Science, pages 416– 432. Springer, 2003.
[BKM18] E. Buchman, J. Kwon, and Z. Milosevic. The latest gossip on BFT consensus, 2018. arXiv:1807.04938, http://arxiv.org/abs/1807.04938.
[BLS01] D. Boneh, B. Lynn, and H. Shacham. Short Signatures from the Weil Pairing. In C. Boyd, editor, Advances in Cryptology - ASIACRYPT 2001, 7th Interna- tional Conference on the Theory and Application of Cryptology and Information Security, Gold Coast, Australia, December 9-13, 2001, Proceedings, volume 2248 of Lecture Notes in Computer Science, pages 514–532. Springer, 2001.
[But13] V. Buterin. Ethereum whitepaper, 2013. https://ethereum.org/en/whitepaper/.
[CDH+21] J. Camenisch, M. Drijvers, T. Hanke, Y.-A. Pignolet, V. Shoup, and D. Williams. Internet Computer Consensus. Cryptology ePrint Archive, Report 2021/632, 2021. https://ia.cr/2021/632.
[CDS94] R. Cramer, I. Damg ̊ard, and B. Schoenmakers. Proofs of Partial Knowledge and Simplified Design of Witness Hiding Protocols. In Advances in Cryptology - CRYPTO ’94, 14th Annual International Cryptology Conference, Santa Bar- bara, California, USA, August 21-25, 1994, Proceedings, volume 839 of Lecture Notes in Computer Science, pages 174–187. Springer, 1994.
[CL99] M. Castro and B. Liskov. Practical Byzantine Fault Tolerance. In M. I. Seltzer and P. J. Leach, editors, Proceedings of the Third USENIX Symposium on Op- erating Systems Design and Implementation (OSDI), New Orleans, Louisiana, USA, February 22-25, 1999, pages 173–186. USENIX Association, 1999.
[CWA+09] A. Clement, E. L. Wong, L. Alvisi, M. Dahlin, and M. Marchetti. Making Byzantine Fault Tolerant Systems Tolerate Byzantine Faults. In J. Rexford and E. G. Sirer, editors, Proceedings of the 6th USENIX Symposium on Networked Systems Design and Implementation, NSDI 2009, April 22-24, 2009, Boston, MA, USA, pages 153–168. USENIX Association, 2009. http://www.usenix.org/events/nsdi09/tech/full_papers/clement/clement.pdf.
[Des87] Y. Desmedt. Society and Group Oriented Cryptography: A New Concept. In C. Pomerance, editor, Advances in Cryptology - CRYPTO ’87, A Conference on the Theory and Applications of Cryptographic Techniques, Santa Barbara, California, USA, August 16-20, 1987, Proceedings, volume 293 of Lecture Notes in Computer Science, pages 120–127. Springer, 1987.
[DLS88] C. Dwork, N. A. Lynch, and L. J. Stockmeyer. Consensus in the presence of partial synchrony. J. ACM, 35(2):288–323, 1988.
[Fis83] M. J. Fischer. The Consensus Problem in Unreliable Distributed Systems (A Brief Survey). In Fundamentals of Computation Theory, Proceedings of the 1983 International FCT-Conference, Borgholm, Sweden, August 21-27, 1983, volume 158 of Lecture Notes in Computer Science, pages 127–140. Springer, 1983.
[FS86] A. Fiat and A. Shamir. How to Prove Yourself: Practical Solutions to Identifica- tion and Signature Problems. In Advances in Cryptology - CRYPTO ’86, Santa Barbara, California, USA, 1986, Proceedings, volume 263 of Lecture Notes in Computer Science, pages 186–194. Springer, 1986.
[GHM+17] Y. Gilad, R. Hemo, S. Micali, G. Vlachos, and N. Zeldovich. Algorand: Scaling Byzantine Agreements for Cryptocurrencies. Cryptology ePrint Archive, Report 2017/454, 2017. https://eprint.iacr.org/2017/454.
[Gro21] J. Groth. Non-interactive distributed key generation and key resharing. Cryp- tology ePrint Archive, Report 2021/339, 2021. https://ia.cr/2021/339.
[JMV01] D. Johnson, A. Menezes, and S. A. Vanstone. The Elliptic Curve Digital Sig- nature Algorithm (ECDSA). Int. J. Inf. Sec., 1(1):36–63, 2001.
[Mer87] R. C. Merkle. A Digital Signature Based on a Conventional Encryption Func- tion. In Advances in Cryptology - CRYPTO ’87, A Conference on the Theory and Applications of Cryptographic Techniques, Santa Barbara, California, USA, August 16-20, 1987, Proceedings, volume 293 of Lecture Notes in Computer Sci- ence, pages 369–378. Springer, 1987.
[MXC^+^16] A. Miller, Y. Xia, K. Croman, E. Shi, and D. Song. The Honey Badger of BFT Protocols. In E. R. Weippl, S. Katzenbeisser, C. Kruegel, A. C. My- ers, and S. Halevi, editors, Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security, Vienna, Austria, October 24-28, 2016, pages 31–42. ACM, 2016.
[Nak08] S. Nakamoto. Bitcoin: A peer-to-peer electronic cash system, 2008. https://bitcoin.org/bitcoin.pdf.
[PS18] R. Pass and E. Shi. Thunderella: Blockchains with Optimistic Instant Con- firmation. In J. B. Nielsen and V. Rijmen, editors, Advances in Cryptology - EUROCRYPT 2018 - 37th Annual International Conference on the Theory and Applications of Cryptographic Techniques, Tel Aviv, Israel, April 29 - May 3, 2018 Proceedings, Part II, volume 10821 of Lecture Notes in Computer Science, pages 3–33. Springer, 2018.
[PSS17] R. Pass, L. Seeman, and A. Shelat. Analysis of the Blockchain Protocol in Asynchronous Networks. In Advances in Cryptology - EUROCRYPT 2017 - 36th Annual International Conference on the Theory and Applications of Cryp- tographic Techniques, Paris, France, April 30 - May 4, 2017, Proceedings, Part II, volume 10211 of Lecture Notes in Computer Science, pages 643–673, 2017.
[Sch90] F. B. Schneider. Implementing Fault-Tolerant Services Using the State Machine Approach: A Tutorial. ACM Comput. Surv., 22(4):299–319, 1990.
[YMR^+^18] M. Yin, D. Malkhi, M. K. Reiter, G. G. Gueta, and I. Abraham. HotStuff: BFT Consensus in the Lens of Blockchain, 2018. arXiv:1803.05069, http://arxiv.org/abs/1803.05069.
- 详见https://webassembly.org/.↩
- 详见https://en.wikipedia.org/wiki/Actor_model.↩
- 详见https://en.wikipedia.org/wiki/Persistence_(computer_science)#Orthogonal_or_transparent_persistence.↩
- 详见 https://en.wikipedia.org/wiki/Transport_Layer_Security.↩
- 但是详见章节8.2↩
- 我们省略的一个细节是,如果在时期中,我们没有收集到所有需要的交易,那么作为备选方案,时期中的下一交易集的值将被设置为时期中的的值。如果这种情况发生,那么协议将酌情使用之前的交易委员会和阈值签名委员会。↩
- 另外需要注意的是,时期中收集的交易取决于时期的摘要块,具体来说,就是和。因此在时期的摘要块被最终确定之前,这些交易不应当生成且不能被验证。↩